-
[Kubernetes Foundation] Kubernetes Control Plane아키텍처 및 기술 공부/Cloud 2022. 9. 29. 00:50반응형
쿠버네티스 클러스터는 컴퓨터의 집합이다. 한 컴퓨터는 "컨트롤 플레인(Control Plane)"이라 하고, 다른 컴퓨터는 "노드"라 한다. 컨트롤 플레인의 작업은 전체 클러스터를 제어하는 것이다.
컨트롤 플레인 컴포넌트
먼저 컨트롤 플레인의 컴포넌트를 살펴보자.
옛날에는 마스터 노드, 워커 노드라 불렸지만, 현재는 컨트롤 플레인 노드, 워커 노드로 명칭이 바뀌었다.
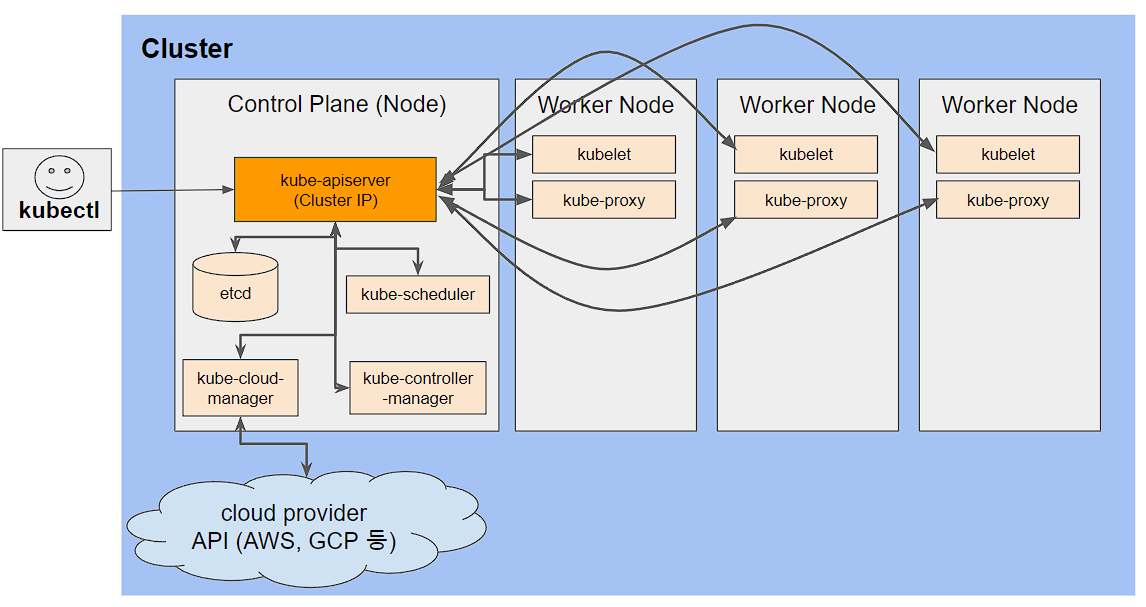
1. kube-apiserver
쿠버네티스 관리자 및 사용자와 직접 상호 작용할 수 있는 단일 구성 요소를 kube-apiserver라 한다. 이 구성요소의 작업은 파드 실행을 포함하여 클러스터의 상태를 보거나 변경 명령을 수락하는 것이다. 이 분야에서는 kubectl 명령을 자주 사용한다. 이 명령어의 역할은 kube-apiserver에 연결하고, 쿠버네티스 API를 사용하여 통신하는 것이다.
2. etcd
etcd는 클러스터의 데이터베이스다. 그 역할은 클러스터의 상태를 안정적으로 저장하는 것이다. 여기에는 모든 클러스터 구성 데이터와 클러스터의 일부인 노드, 실행해야 하는 파드, 실행해야 하는 위치와 같은 보다 동적인 정보까지 포함된다. 쿠버네티스 관리자 및 사용자는 etcd와는 직접 상호작용하지 않고 kube-apiserver가 데이터베이스와 대신 상호작용한다.
3. kube-scheduler
kube-scheduler는 노드에 파드를 예약하는 역할을 한다. 이를 위해 각 개별 파드의 요구사항을 평가하고 가장 적합한 노드를 선택한다. 그러나 실제로 노드에서 파드를 시작하는 작업을 수행하진 않는다. 노드에 아직 할당되지 않은 파드 오브젝트를 발견할 때마다 노드를 선택하고 해당 노드의 이름을 파드 오브젝트에 작성한다. 그러면 다른 구성요소(kube-controller-manager)가 파드를 실행하는 역할을 한다.
kube-scheduler는 파드를 실행할 위치를 어떻게 결정할까? kube-scheduler는 모든 노드의 상태를 알고 있으며 하드웨어, 소프트웨어, 정책을 기반으로 파드가 실행될 위치에 대해 정의한 제약 조건을 따른다. 특정 파드가 특정 크기의 메모리가 있는 노드에서만 실행되도록 지정할 수 있다. 또한 어피니티(Affinity) 사양을 정의하여 파드 그룹이 동일한 노드에서 실행하는 것을 선호하게 하거나, 안티 어피니티(Anti-Affinity)를 사양을 정의하여 파드가 동일한 노드에서 실행되지 않도록 할 수 있다.
4. kube-controller-manager
kube-controller-manager는 더 광범위한 작업을 수행한다. kube-apiserver를 통해 클러스터 상태를 지속적으로 모니터링한다. 클러스터의 현재 상태가 원하는 상태와 일치하지 않을 때마다 kube-controller-manager는 원하는 상태를 달성하기 위해 변경을 시도한다. 많은 쿠버네티스 오브젝트(Object)가 컨트롤러라는 *코드 루프에 의해 관리된다. (컨트롤 루프라고도 불린다.)
5. cloud-controller-manager
클라우드 컨트롤러 매니저를 통해 클러스터를 클라우드 공급자의 API에 연결하고, 해당 클라우드 플랫폼과 상호 작용하는 컴포넌트와 클러스터와만 상호 작용하는 컴포넌트를 구분할 수 있게 해준다.
6. GKE 자랑
쿠버네티스 클러스터를 수동으로 설정하는 것은 많은 작업이 필요하다. 다행히 클러스터의 초기 설정을 대부분 자동화할 수 있는 kubeadm이라는 오픈소스 명령어가 있다. 하지만 노드에 장애가 발생하거나 유지관리가 필요한 경우 관리자가 수동으로 작업해야 한다. GKE는 우리를 위해 모든 컨트롤 플레인 구성요소를 관리한다. 여전히 모든 쿠버네티스 API 요청을 보내는 Cluster IP 주소를 노출한다. 그러나 GKE는 모든 제어 영역 인프라를 프로비저닝하고 관리하는 책임을 진다.
모든 쿠버네티스 환경에서 노드는 쿠버네티스 자체가 아니라 클러스터 관리자가 외부적으로 생성한다. 여러 노드 풀을 만들어 여러 노드 머신을 선택할 수도 있다. 노드 풀은 메모리 크기 또는 CPU 생성과 같은 구성을 공유하는 클러스터 내 노드의 하위 집합입니다. 또한 노드 풀은 워크로드가 클러스터 내의 올바른 하드웨어에서 실행되도록 하는 쉬운 방법을 제공한다. 원하는 노드 풀로 레이블을 지정하기만 하면 된다. 그런데 노드 풀은 쿠버네티스 기능이 아니라 GKE 기능이다. 오픈 소스 쿠버네티스 내에서 유사한 메커니즘을 구축할 수 있지만 직접 유지 관리해야 한다. 이 노드 풀 수준에서 자동 노드 업그레이드, 자동 노드 복구 및 클러스터 자동 확장을 사용 설정할 수 있다.
전체 컴퓨팅 영역이 다운되면 어떻게 되나?
GKE 지역 클러스터(Regional Clusters)를 사용하여 이 문제를 해결할 수 있다. 지역 클러스터에는 클러스터에 대한 단일 API 엔드포인트가 있다. 그러나 컨트롤 플레인과 노드는 지역(region) 내의 여러 Compute Engine 영역(Zone)에 분산되어 있다. 지역 클러스터는 단일 지역의 여러 영역에서 애플리케이션의 가용성이 유지되도록 한다. 또한 컨트롤 플레인의 가용성도 유지되므로 애플리케이션과 관리 기능이 하나 이상의 영역 손실을 견딜 수 있다. 기본적으로 지역 클러스터는 각각 (1개의 제어 영역과 3개의 노드)를 포함하는 3개의 영역에 분산되어 있다.
참고자료:
* 컨트롤러라는 코드 루프, 컨트롤 루프: https://kubernetes.io/ko/docs/concepts/architecture/controller/
https://kubernetes.io/ko/docs/concepts/overview/components/
반응형'아키텍처 및 기술 공부 > Cloud' 카테고리의 다른 글
[Kubernetes Workloads] 디플로이먼트(Deployment) (0) 2022.10.08 [Kubernetes Foundation] Object Management (0) 2022.09.29 [Kubernetes Foundation] Kubernetes (0) 2022.09.25 [Kubernetes Foundation] Container (0) 2022.09.24 [Kubernetes Foundation] Interacting with Google Cloud & quotas (1) 2022.09.21